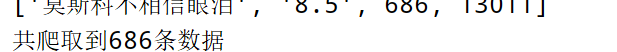from ssl import _create_unverified_context
from json import loads
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tkinter.messagebox
import urllib.request
import urllib.parse
movieData = ' [' \
'{"title":"纪录片", "type":"1", "interval_id":"100:90"}, ' \
' {"title":"传记", "type":"2", "interval_id":"100:90"}, ' \
' {"title":"犯罪", "type":"3", "interval_id":"100:90"}, ' \
' {"title":"历史", "type":"4", "interval_id":"100:90"}, ' \
' {"title":"动作", "type":"5", "interval_id":"100:90"}, ' \
' {"title":"情色", "type":"6", "interval_id":"100:90"}, ' \
' {"title":"歌舞", "type":"7", "interval_id":"100:90"}, ' \
' {"title":"儿童", "type":"8", "interval_id":"100:90"}, ' \
' {"title":"悬疑", "type":"10", "interval_id":"100:90"}, ' \
' {"title":"剧情", "type":"11", "interval_id":"100:90"}, ' \
' {"title":"灾难", "type":"12", "interval_id":"100:90"}, ' \
' {"title":"爱情", "type":"13", "interval_id":"100:90"}, ' \
' {"title":"音乐", "type":"14", "interval_id":"100:90"}, ' \
' {"title":"冒险", "type":"15", "interval_id":"100:90"}, ' \
' {"title":"奇幻", "type":"16", "interval_id":"100:90"}, ' \
' {"title":"科幻", "type":"17", "interval_id":"100:90"}, ' \
' {"title":"运动", "type":"18", "interval_id":"100:90"}, ' \
' {"title":"惊悚", "type":"19", "interval_id":"100:90"}, ' \
' {"title":"恐怖", "type":"20", "interval_id":"100:90"}, ' \
' {"title":"战争", "type":"22", "interval_id":"100:90"}, ' \
' {"title":"短片", "type":"23", "interval_id":"100:90"}, ' \
' {"title":"喜剧", "type":"24", "interval_id":"100:90"}, ' \
' {"title":"动画", "type":"25", "interval_id":"100:90"}, ' \
' {"title":"同性", "type":"26", "interval_id":"100:90"}, ' \
' {"title":"西部", "type":"27", "interval_id":"100:90"}, ' \
' {"title":"家庭", "type":"28", "interval_id":"100:90"}, ' \
' {"title":"武侠", "type":"29", "interval_id":"100:90"}, ' \
' {"title":"古装", "type":"30", "interval_id":"100:90"}, ' \
' {"title":"黑色电影", "type":"31", "interval_id":"100:90"}' \
']'
class getMovieInRankingList:
def __init__(self):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument(
'user-agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"')
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
chrome_options.add_experimental_option("prefs",{"profile.managed_default_content_settings.images": 2})
try:
self.browser = webdriver.Chrome(executable_path='C:\chromedriver_win32\chromedriver.exe',options=chrome_options)
self.wait = WebDriverWait(self.browser, 10)
except:
print("chromedriver.exe出错,请检查是否与你的chrome浏览器版本相匹配\n缺失chromedriver.exe不会导致从排行榜搜索功能失效,但会导致从关键字搜索功能失效")
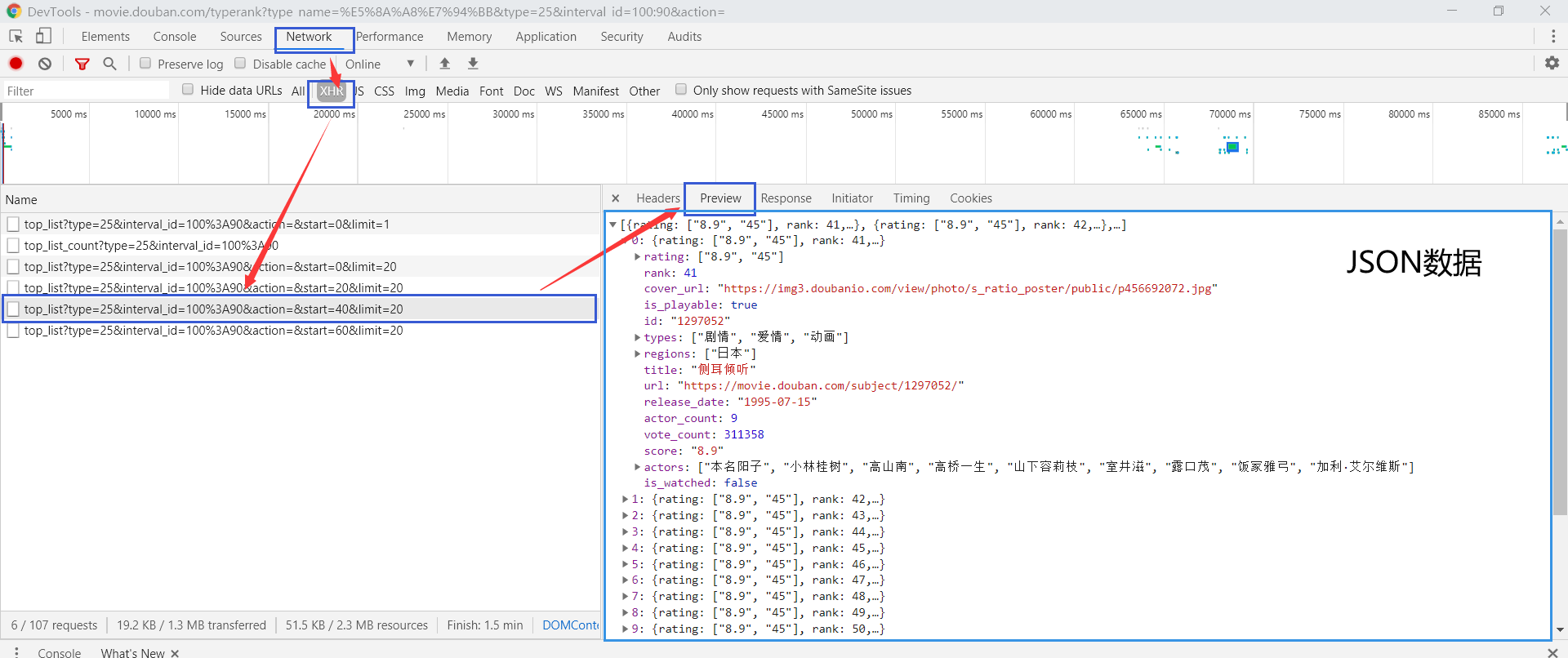
def get_url_data_in_ranking_list(self, typeId,title, movie_count, rating, vote_count):
context = _create_unverified_context()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', }
url = 'https://movie.douban.com/j/chart/top_list?type=' + str(
typeId) + '&interval_id=100:90&action=unwatched&start=0&limit=' + str(movie_count)
req = urllib.request.Request(url=url, headers=headers)
f = urllib.request.urlopen(req, context=context)
response = f.read()
jsonData = loads(response)
list = []
for subData in jsonData:
if ((float(subData['rating'][0]) >= float(rating))and(float(subData['vote_count'])>=float(vote_count))):
subList = []
subList.append(subData['title'])
subList.append(subData['rating'][0])
subList.append(subData['rank'])
subList.append(subData['vote_count'])
list.append(subList)
for data in list:
print(data)
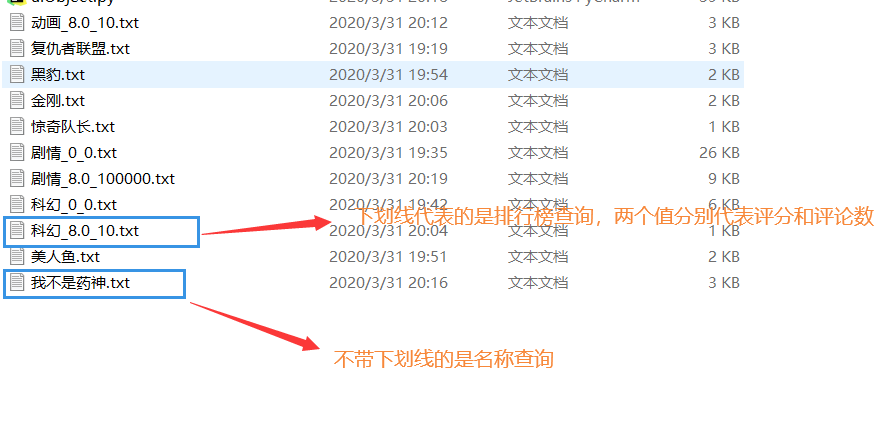
f = open("./" + title+ "_"+rating+"_"+vote_count+".txt", "w", encoding="utf-8")
sample_list = [str(line) + '\n' for line in list]
f.writelines(sample_list)
f.close()
print('共爬取到' + str(list.__len__()) + '条数据')
return list, jsonData
def get_url_data_in_keyWord(self, key_word):
self.browser.get('https://movie.douban.com/subject_search?search_text=' + urllib.parse.quote(
key_word) + '&cat=1002')
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.root')))
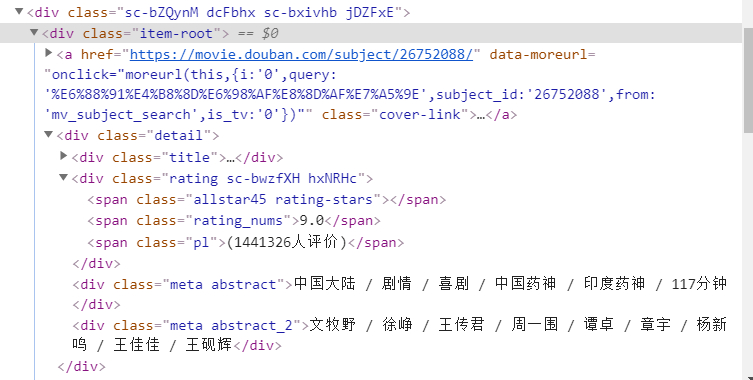
dr = self.browser.find_elements_by_xpath("//div[@class='item-root']")
jsonData = []
list = []
for son in dr:
movieData = {'rating': ['', 'null'], 'cover_url': '', 'types': '', 'title': '', 'url': '',
'release_date': '', 'vote_count': '', 'actors': ''}
subList = ['', '', '', '']
url_element = son.find_elements_by_xpath(".//a")
if (url_element):
movieData['url'] = (url_element[0].get_attribute("href"))
img_url_element = url_element[0].find_elements_by_xpath(".//img")
if (img_url_element):
movieData['cover_url'] = (img_url_element[0].get_attribute("src"))
title_element = son.find_elements_by_xpath(".//div[@class='title']")
if (title_element):
temp_title = (title_element[0].text)
movieData['title'] = (temp_title.split('('))[0]
movieData['release_date'] = temp_title[temp_title.find('(') + 1:temp_title.find(')')]
subList[0] = movieData['title']
rating_element = son.find_elements_by_xpath(".//span[@class='rating_nums']")
if (rating_element):
movieData['rating'][0] = (rating_element[0].text)
subList[1] = movieData['rating'][0]
vote_element = son.find_elements_by_xpath(".//span[@class='pl']")
if (vote_element):
movieData['vote_count'] = (vote_element[0].text).replace('(', '').replace(')', '').replace('人评价', '')
subList[3] = movieData['vote_count']
type_element = son.find_elements_by_xpath(".//div[@class='meta abstract']")
if (type_element):
movieData['types'] = (type_element[0].text)
subList[2] = movieData['types']
actors_element = son.find_elements_by_xpath(".//div[@class='meta abstract_2']")
if (actors_element):
movieData['actors'] = (actors_element[0].text)
jsonData.append(movieData)
list.append(subList)
self.browser.quit()
for data in list:
print(data)
print('共爬取到'+str(list.__len__())+'条数据')
f = open("./" +key_word+".txt", "w",encoding="utf-8")
sample_list = [str(line)+'\n' for line in list]
f.writelines(sample_list)
f.close()
return list, jsonData
def BinarySearch(strs,filename):
f = open(filename,"r",encoding='utf-8')
line = f.readline()
cnt = 0
dic = {}
list = []
while line:
line = line[2:line.find("'",2)]
line = line.rstrip()
dic[line] = cnt
cnt = cnt+1
line = f.readline()
low = 0
high = cnt-1
flag = 0
for key in dic.keys():
if key == strs:
flag = 1
break
if flag == 0:
print("不存在这部电影")
return 0
while low <= high:
mid = (low+high)/2
if dic[strs] < mid:
high = mid - 1
elif dic[strs] > mid:
low = mid +1
else:
print('找到电影,其在对应文件的行号为' ,int(mid+1))
return 0
if __name__ == "__main__":
print('**************1.排行榜爬取***************')
print('**************2.电影名称爬取**************')
print('**************3.退出********************')
choice = input('请选择')
while choice != '3':
if(choice == '2'):
print('蜘蛛侠即将到达战场,请稍等···')
movie = getMovieInRankingList()
moviename = input("请输入要爬取的电影的名称:")
print('数据爬取并写入文件,请等待···')
movie.get_url_data_in_keyWord(moviename)
strs = input('请输入搜索的电影名称(二分查找):')
filename = moviename+'.txt'
res = BinarySearch(strs,filename)
print('------------------------------------------------')
elif(choice == '1'):
print('蜘蛛侠即将到达战场,请稍等···')
movie = getMovieInRankingList()
typeId = input('请输入类型:')
title = input('请输入电影类别:')
movie_count = input('请输入爬取数量:')
rating = input('请输入评分:')
vote_count = input('请输入评论数:')
movie.get_url_data_in_ranking_list(typeId,title,movie_count,rating,vote_count)
print('数据爬取并写入文件,请等待···')
print('------------------------------------------------')
choice = input('请选择')
|