一.课题开展的意义
深度强化学习与其他学习方式不同,它不仅关心一个独立的,被动的主体如何学习,还强调一个完整的只能主体要与环境不停地互动,从而展现出智能特性。所以,强化学习知道的智能主体天然具备两点重要特性:做中学(learning by doing)以及长短期回报的综合与协调。值得注意的是,在现实生活中,我们每个人都是一个强化学习主体,因为我们是在与环境地不断互动中完成学习的。与其他学习方法相比,强化学习模型的学习更像是在描述一个抽象的智能体思考和决策的过程。它并不局限在一个特定的学习问题上,而是可以扩展到多个领域。因此,强化学习被普遍认为是终极人工智能之梦——通用人工智能(artificial general intelligence)。
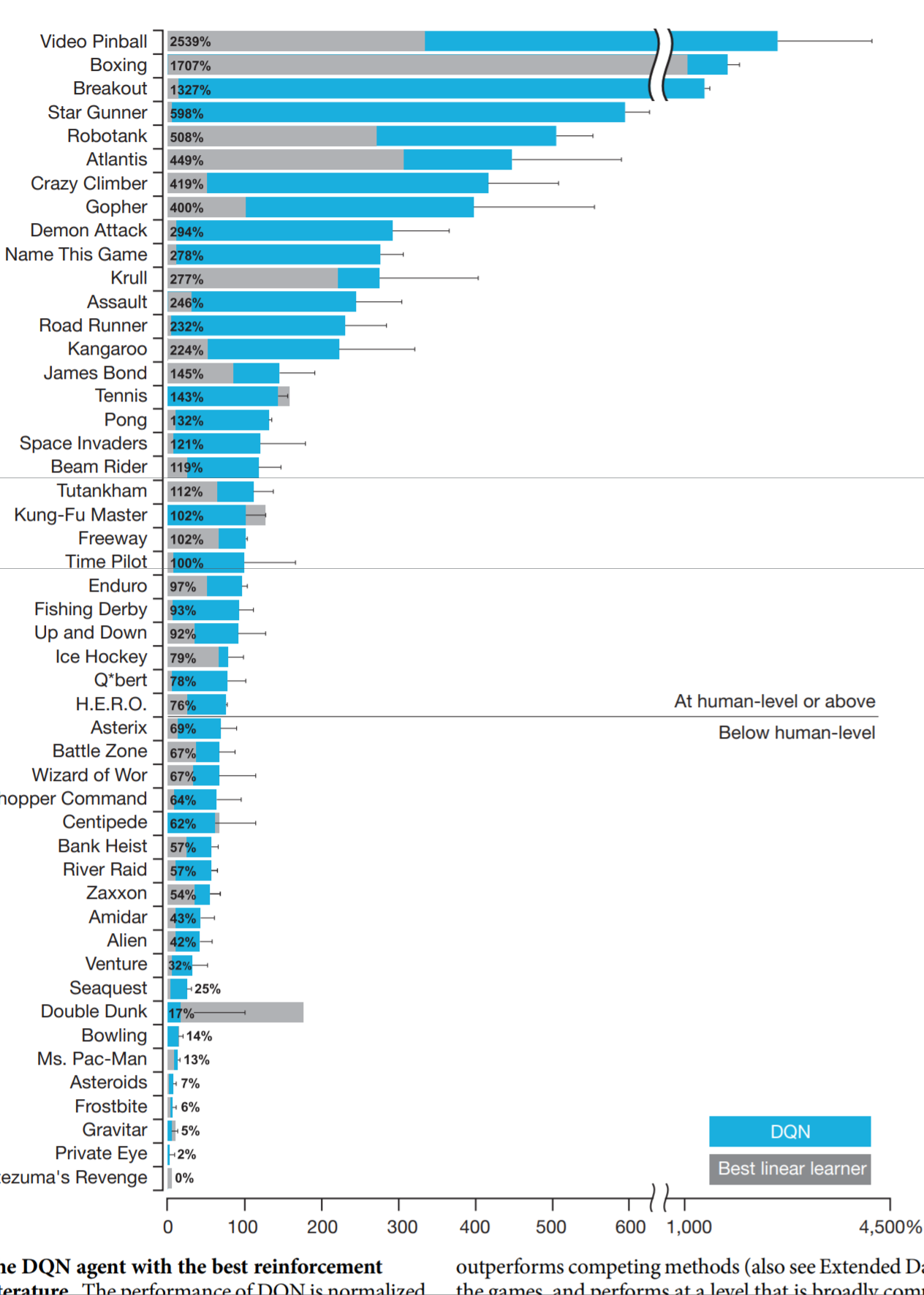
这一领域不仅是举世瞩目的AlphaGo 和 AlphaGo Zero赖以驰骋旗场的基础,而且是目前人工智能研究的前沿。
二.Q-Learning算法
Q-Learning 就是要学习在一个给定的 state 时,采取了一个特定的行动后,能得到的奖励是什么。
这时可以用一个表格来记录每组 state 和 action 时的值,
这个表,首先被初始化为 0,
然后每走一步,都相应地更新表格,
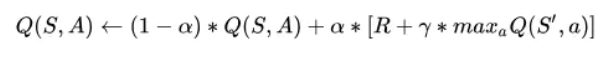
其中更新的方法是用 Bellman Equation:
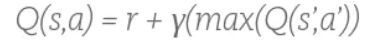
其中,
S 代表当前的状态,a 代表当前状态所采取的行动,
S’ 代表这个行动所引起的下一个状态,a’ 是这个新状态时采取的行动,
r 代表采取这个行动所得到的奖励 reward,γ 是 discount 因子,
由公式可以看出 s,a 对的 Q 值等于 即时奖励 + 未来奖励的 discount。
γ 决定了未来奖励的重要性有多大,
比如说,我们到了一个状态,它虽然离目标状态远了一些,但是却离炸弹远了一些,那这个状态的即时奖励就很小,但是未来奖励就很多。
算法是:
- 初始化 Q table 为 0
- 每一次遍历,随机选择一个状态作为起点
- 在当前状态 (S) 的所有可选的行动中选择一个 (a)
- 移动到下一个状态 (S’)
- 在新状态上选择 Q 值最大的那个行动 (a’)
- 用 Bellman Equation 更新 Q-table
- 将新状态设置为当前状态重复第 2~6 步
- 如果已经到了目标状态就结束
三.DQN网络
常规的Q-table碰到大量的参数时将无法设定,所以就要引入神经网络来优化Q-learning算法。
所谓DQN网络就是利用利用卷积神经网络和Epsilon贪婪测率对游戏进行训练,从而不断地去更新D五元组,让模型找到最优的reward,训练让小鸟不断地朝着更好奖励的方向去调整自己的飞行状态。
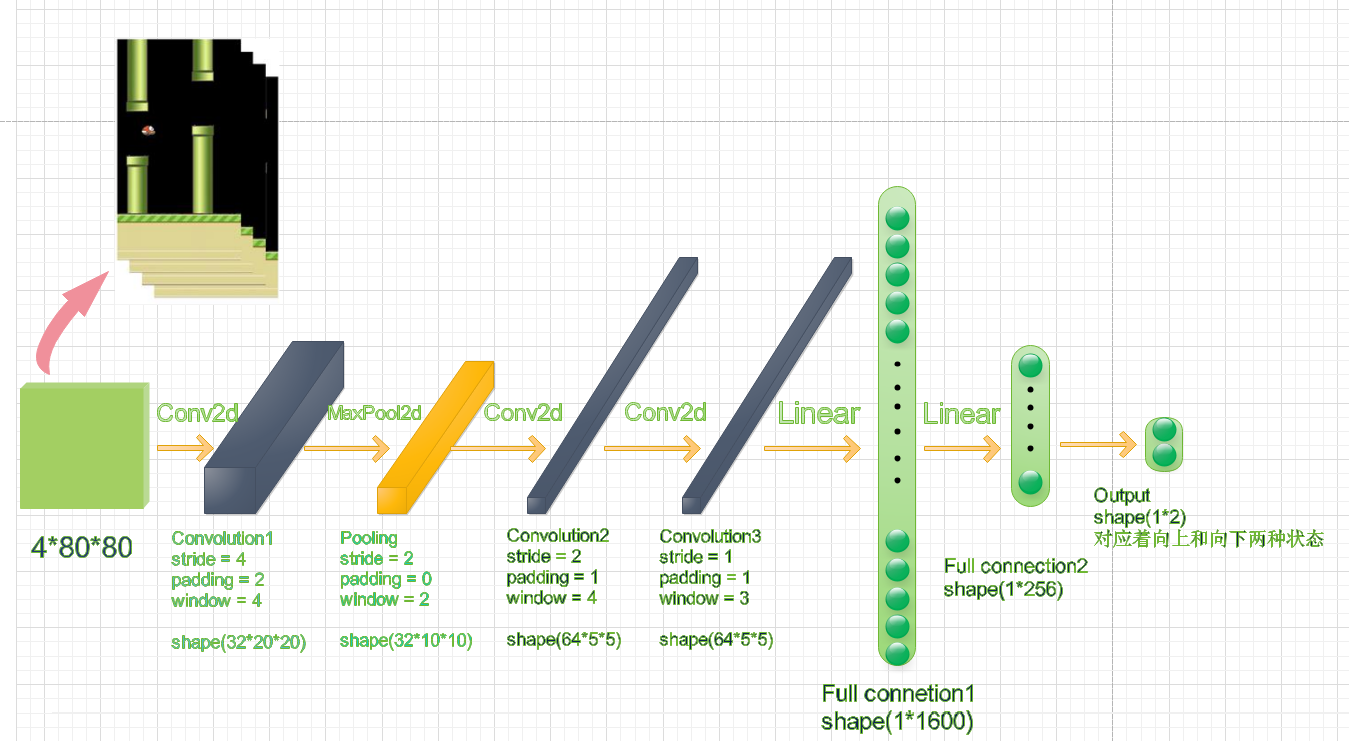
注:第一层卷积层的窗口大小为8
四.实现结果
实际运行状态:
训练3000000次的reward:
可以看到在训练2.5M次后,模型的reward的提升有了明显的加快。
训练5000000次的reward:
在经历了大约49小时后,模型可以的奖励分值可以达到300+。
FlappyBird最高得分可以达到1000+;
取平均值后,FlappyBird均分为140+;
 *
*