一.NPLM:神经语言概率模型
我们需要一种能避免几种传统编码方式缺陷的模型。我们希望,经过这个模型编码后的词向量长度固定,但不需要太长。另外,向量最好是密集的,也就是0元素要尽可能少,不要浪费存储空间。实际上,NPLM模型刚好可以满足我们的要求。
首先来看几个可能的例子。
“太阳”经NPLM模型编码后的词向量可能是【0.40,0.34,-0.17,0.88】;
“月亮”经NPLM模型编码后的词向量可能是【0.41,0.30,0.55,0.90】;
“猫’’ 经NPLM模型编码后的词向量可能是【0.01,-0.50,-0.95,0.20】;
每个词向量的维度都是一样的。从语义上来说,”太阳“和”月亮“在向量空间中的距离更近。”猫“与”太阳“和”月亮“的距离很远。这是我们想要的结果。
1.1 NPLM的基本思想
NPLM是一个基于神经网络的语言模型,有趣的是,这个模型的本意并不是获取词向量的而是用读到的前几个词去预测下一个词的。词向量只不过是NPLM模型的副产品。
在学习NPLM模型之前,我们需要先简单了解一个自然语言处理中非常重要的概念N-gram模型,也叫N元语言模型。Ngam模型假设一个词语的出现只和它前面的N个词语相关按照这个假设,我们可以根据前N个词语去预测当前的词语。比如在“天空的颜色大是”这句话中,我们根据“天空”“的”“颜色”“是”这4个词语,很容易预测下一个词语是“蓝色果将这个过程抽象为N-gram模型运算过程,我们可以知道此处的N被设置为4也就是说,一个4-gram模型就可以解决当前问题。
N-gram模型在自然语言处理领域中的应用非常广泛。理论上,我们希望能够以非常大的N 来建立N-gram模型,因为有的词语和前面的联系非常远,例如,“最近小镇旁边建立的工厂违规排放废气,造成了严重的大气污染,这里的天空的颜色是”。此处,如果用4-gram模型,我们依然会在空白处填为“蓝色”,但是如果N被设置得非常大,模型就可能会考虑“污染”“废气等词语的影响,而将此处填为“灰色”。事实上,在实际应用的过程中,将N设置得越大,模型的运算就越慢,所以在一般的项目中,我们通常将N设置为2或3。将N设置为3即可在大部分自然语言处理任务中取得较好的效果。
在下面的例子中,我们就选用3-gram模型,将其应用到NPLM网络中,即我们假设当前词的出现与它前面的3个词有关由此可见,N-gram模型的本质就是一个映射函数,它把前N个单词映射到下一个单词f( w,w2,…,WN)= W N+1,而NPLM想要做的,就是用一个神经网络通过机器学习的方式来学到这个映射函数f。
非常有意思的是,NPLM在完成这个学习任务之后,我们就可以在这个神经网络中“读出”每个单词的向量编码了。换句话说,词向量不过是NPLM的一个副产品。
1.2 NPLM实战
首先,我们构建了一个简单的NGram语言模型,根据N个历史词汇预测下一个单词,从而得到每一个单词的向量表示。我们用小说《三体》为例,展示了我们的词向量嵌入效果。
其次,我们学习了如何使用成熟的Google开发的Word2Vec包来进行大规模语料的词向量训练,以及如何加载已经训练好的词向量,从而利用这些词向量来做一些简单的运算和测试。
# 加载必要的程序包 |
1. 文本预处理
我们以刘慈欣著名的科幻小说《三体》为例,来展示利用NGram模型训练词向量的方法
预处理分为两个步骤:
1、读取文件
2、分词
3、将语料划分为N+1元组,准备好训练用数据
在这里,我们并没有去除标点符号,一是为了编程简洁,而是考虑到分词会自动将标点符号当作一个单词处理,因此不需要额外考虑。
#读入原始文件 |
我们构造了一个三层的网络:
1、输入层:embedding层,这一层的作用是:先将输入单词的编号映射为一个one hot编码的向量,形如:001000,维度为单词表大小。 然后,embedding会通过一个线性的神经网络层映射到这个词的向量表示,输出为embedding_dim
2、线性层,从embedding_dim维度到128维度,然后经过非线性ReLU函数
3、线性层:从128维度到单词表大小维度,然后log softmax函数,给出预测每个单词的概率
class NGram(nn.Module): |
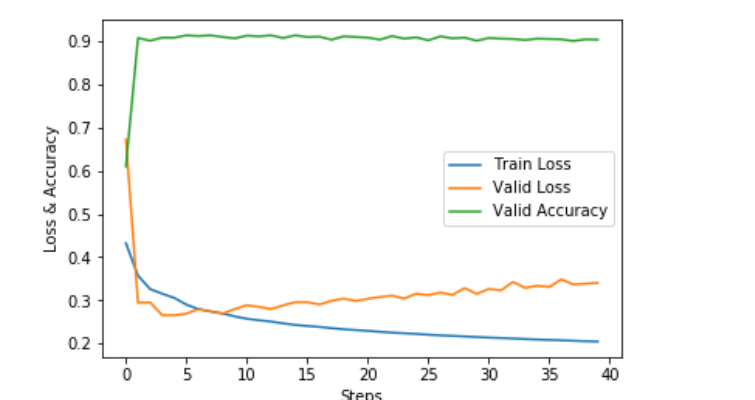
结果展示
# 从训练好的模型中提取每个单词的向量 |

可以看到,这些词语在语义上并没有什么关联,这说明我们的NPLM模型学出来的词向量并不好
1.3 NPLM的总结与局限
我们可以这样理解NPLM的网络原理。实际上,它接受的输入是独热编码,在运作过程中,会先尝试将这个独热编码映射为一个特定维数的词向量,然后再用词向量取预测可能出现在这个词后面的词。随着训练次数的增加和反向传播的调整,网络渐渐获取了将意义相近的词映射为相似的词向量的能力。
缺点:速度太慢。NPLM于2003年诞生,但正是由于这个缺陷,没有得到广泛使用。
二 .Word2Vec
2.1 Word2Vec 介绍
word2vec是NPLM的升级版,它在多方面进行了改进,大幅提升了NPLM模型的运算速度和精度。
Word2Vec是一组(2个)模型,分别叫做CBOW(continuous bag of words)模型和Skip-gram模型。
- CBOW:用当前词的前n个词和后n个词来预测当前的词。
- Skip-gram:和CBOW相反,用当前词预测上下文。
2.2 层级软最大
在NPLM模型中,输出层单元用一层神经元来对应当前词,这种结构对于当前词的查询和反馈都是比较耗时的。层级软最大(hierarchical softmax)的核心思路是对输出层单元的结构进行更改,将其由原来的“扁平结构”编码为一个哈夫曼树(Huffman tree),树中的每一个叶节点对应一个词语。
如果词典中有n个词,输出层经过哈夫曼编码后,只需要经过log(n)步即可查询到该词。而且,在每次训练的反馈过程中,都会更新从根节点到当前词对应的叶节点的所有连边的权值,这也加速了网络的training.
2.3 负采样
层级软最大改进了输出层结构,而负采样则改进了目标函数。
核心思路:在训练过程汇总,我们不知道哪个词是正确的,而且知道随机选取的词应该是错误的。在每次训练的过程中,我们可以随机选取多个负样本一同参与损失函数的计算,模型就会同时考虑正负样本的影响。
2.4 Word2vec实战
# 读入文件、分词,形成一句一句的语料 |
星空图如下:
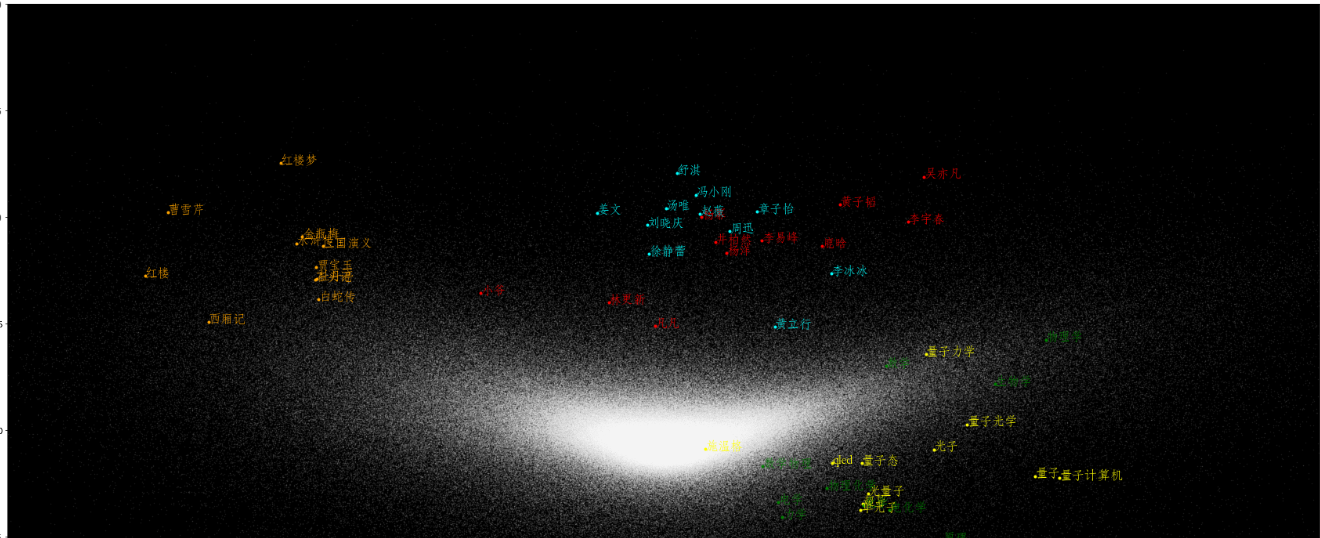
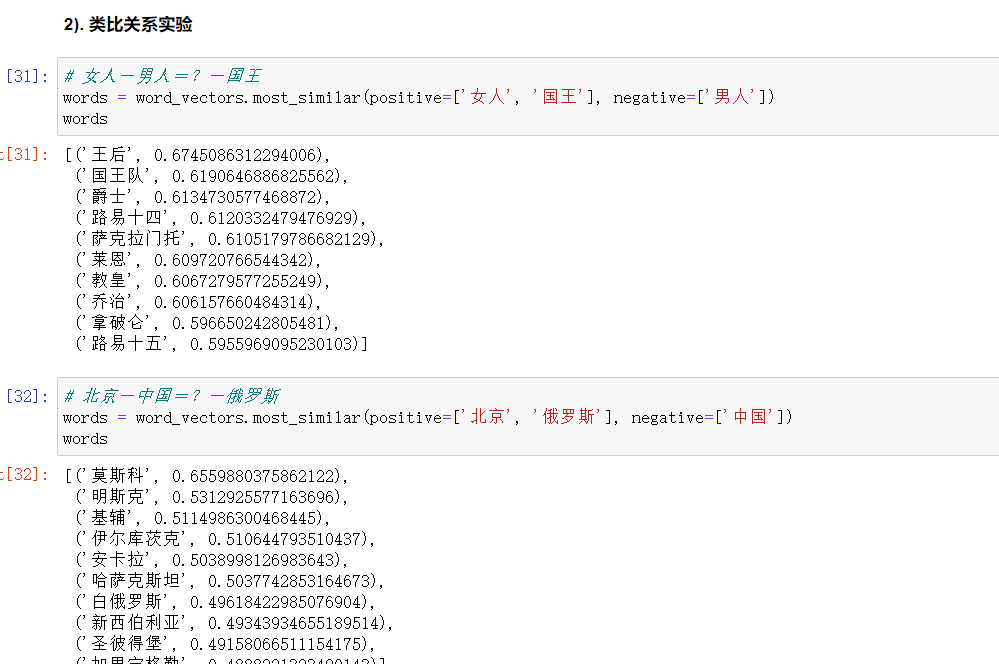
2.5 类比关系实验