j = 0 for bad_comment_url_template in bad_comment_url_templates: for i in range(100): url = bad_comment_url_template.format(i) bad_comments += get_comments(url) print('第{}条纪录,总文本长度{}'.format(j, len(bad_comments))) j += 1
#扫描所有的文本,分词、建立词典,分出正向还是负向的评论,is_filter可以过滤是否筛选掉标点符号 defPrepare_data(good_file, bad_file, is_filter = True): all_words = [] #存储所有的单词 pos_sentences = [] #存储正向的评论 neg_sentences = [] #存储负向的评论 with open(good_file, 'r') as fr: for idx, line in enumerate(fr): if is_filter: #过滤标点符号 line = filter_punc(line) #分词 words = jieba.lcut(line) if len(words) > 0: all_words += words pos_sentences.append(words) print('{0} 包含 {1} 行, {2} 个词.'.format(good_file, idx+1, len(all_words)))
count = len(all_words) with open(bad_file, 'r') as fr: for idx, line in enumerate(fr): if is_filter: line = filter_punc(line) words = jieba.lcut(line) if len(words) > 0: all_words += words neg_sentences.append(words) print('{0} 包含 {1} 行, {2} 个词.'.format(bad_file, idx+1, len(all_words)-count))
#建立词典,diction的每一项为{w:[id, 单词出现次数]} diction = {} cnt = Counter(all_words) for word, freq in cnt.items(): diction[word] = [len(diction), freq] print('字典大小:{}'.format(len(diction))) return(pos_sentences, neg_sentences, diction)
#根据单词返还单词的编码 defword2index(word, diction): if word in diction: value = diction[word][0] else: value = -1 return(value)
#根据编码获得单词 defindex2word(index, diction): for w,v in diction.items(): if v[0] == index: return(w) return(None)
pos_sentences, neg_sentences, diction = Prepare_data(good_file, bad_file, True) st = sorted([(v[1], w) for w, v in diction.items()]) st
# 输入一个句子和相应的词典,得到这个句子的向量化表示 # 向量的尺寸为词典中词汇的个数,i位置上面的数值为第i个单词在sentence中出现的频率 defsentence2vec(sentence, dictionary): vector = np.zeros(len(dictionary)) for l in sentence: vector[l] += 1 return(1.0 * vector / len(sentence))
# 遍历所有句子,将每一个词映射成编码 dataset = [] #数据集 labels = [] #标签 sentences = [] #原始句子,调试用 # 处理正向评论 for sentence in pos_sentences: new_sentence = [] for l in sentence: if l in diction: new_sentence.append(word2index(l, diction)) dataset.append(sentence2vec(new_sentence, diction)) labels.append(0) #正标签为0 sentences.append(sentence)
# 处理负向评论 for sentence in neg_sentences: new_sentence = [] for l in sentence: if l in diction: new_sentence.append(word2index(l, diction)) dataset.append(sentence2vec(new_sentence, diction)) labels.append(1) #负标签为1 sentences.append(sentence)
#打乱所有的数据顺序,形成数据集 # indices为所有数据下标的一个全排列 indices = np.random.permutation(len(dataset))
#重新根据打乱的下标生成数据集dataset,标签集labels,以及对应的原始句子sentences dataset = [dataset[i] for i in indices] labels = [labels[i] for i in indices] sentences = [sentences[i] for i in indices]
defrightness(predictions, labels): """计算预测错误率的函数,其中predictions是模型给出的一组预测结果,batch_size行num_classes列的矩阵,labels是数据之中的正确答案""" pred = torch.max(predictions.data, 1)[1] # 对于任意一行(一个样本)的输出值的第1个维度,求最大,得到每一行的最大元素的下标 rights = pred.eq(labels.data.view_as(pred)).sum() #将下标与labels中包含的类别进行比较,并累计得到比较正确的数量 return rights, len(labels) #返回正确的数量和这一次一共比较了多少元素
训练模型
# 损失函数为交叉熵 cost = torch.nn.NLLLoss() # 优化算法为Adam,可以自动调节学习率 optimizer = torch.optim.Adam(model.parameters(), lr = 0.01) records = []
#循环10个Epoch losses = [] for epoch in range(10): for i, data in enumerate(zip(train_data, train_label)): x, y = data # 需要将输入的数据进行适当的变形,主要是要多出一个batch_size的维度,也即第一个为1的维度 x = torch.tensor(x, requires_grad = True, dtype = torch.float).view(1,-1) # x的尺寸:batch_size=1, len_dictionary # 标签也要加一层外衣以变成1*1的张量 y = torch.tensor(np.array([y]), dtype = torch.long) # y的尺寸:batch_size=1, 1 # 清空梯度 optimizer.zero_grad() # 模型预测 predict = model(x) # 计算损失函数 loss = cost(predict, y) # 将损失函数数值加入到列表中 losses.append(loss.data.numpy()) # 开始进行梯度反传 loss.backward() # 开始对参数进行一步优化 optimizer.step() # 每隔3000步,跑一下校验数据集的数据,输出临时结果 if i % 3000 == 0: val_losses = [] rights = [] # 在所有校验数据集上实验 for j, val in enumerate(zip(valid_data, valid_label)): x, y = val x = torch.tensor(x, requires_grad = True, dtype = torch.float).view(1,-1) y = torch.tensor(np.array([y]), dtype = torch.long) predict = model(x) # 调用rightness函数计算准确度 right = rightness(predict, y) rights.append(right) loss = cost(predict, y) val_losses.append(loss.data.numpy()) # 将校验集合上面的平均准确度计算出来 right_ratio = 1.0 * np.sum([i[0] for i in rights]) / np.sum([i[1] for i in rights]) print('第{}轮,训练损失:{:.2f}, 校验损失:{:.2f}, 校验准确率: {:.2f}'.format(epoch, np.mean(losses), np.mean(val_losses), right_ratio)) records.append([np.mean(losses), np.mean(val_losses), right_ratio])
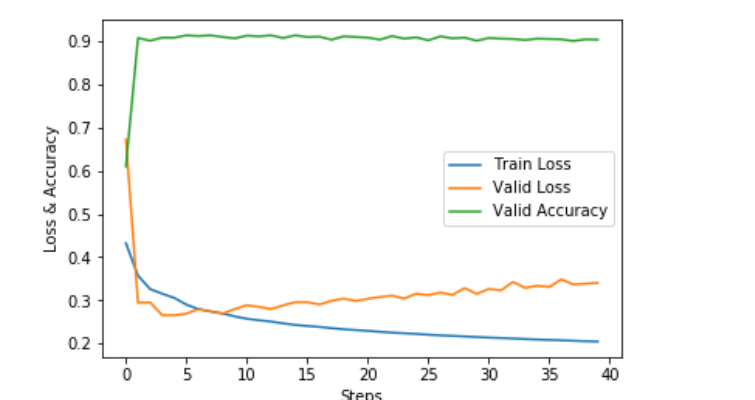
# 绘制误差曲线 a = [i[0] for i in records] b = [i[1] for i in records] c = [i[2] for i in records] plt.plot(a, label = 'Train Loss') plt.plot(b, label = 'Valid Loss') plt.plot(c, label = 'Valid Accuracy') plt.xlabel('Steps') plt.ylabel('Loss & Accuracy') plt.legend()
#在测试集上分批运行,并计算总的正确率 vals = [] #记录准确率所用列表
#对测试数据集进行循环 for data, target in zip(test_data, test_label): data, target = torch.tensor(data, dtype = torch.float).view(1,-1), torch.tensor(np.array([target]), dtype = torch.long) output = model(data) #将特征数据喂入网络,得到分类的输出 val = rightness(output, target) #获得正确样本数以及总样本数 vals.append(val) #记录结果
#计算准确率 rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals])) right_rate = 1.0 * rights[0].data.numpy() / rights[1] right_rate